

What is PrivateGPT
Imagine if you could take your organization’s collective knowledge, parse it, index it and enable you to gain deeper and better insights, all in a manner where you control the sovereignty of that data; wouldn’t it make you curious about the power that could bring to your organization?
PrivateGPT (short for Private Generative Pre-Trained) is a relatively new AI model architecture that has gained significant attention in the AI community. It’s designed to address some of the limitations and concerns about data sovereignty
In essence, PrivateGPT is a modification of the original GPT (Generative Pre-Trained) architecture, with a focus on maintaining privacy and confidentiality during model training and deployment.
Here are some key features that set PrivateGPT apart:
- Private data processing: PrivateGPT uses homomorphic encryption techniques to process private data in a secure manner. This means that even the AI model itself doesn’t have access to the sensitive information, ensuring that it remains confidential.
- Distributed training: To mitigate the risk of data leakage during training, PrivateGPT employs a distributed architecture where multiple machines are involved in the training process. Each machine receives a partial view of the data and collaborates with others to compute the gradients.
- Secure aggregation: During model updates, PrivateGPT uses secure aggregation techniques to combine the local models without revealing any information about individual contributions.
The primary goals of PrivateGPT are:
- Data protection: Ensure that sensitive information remains confidential and protected during training and deployment.
- Model trustworthiness: Maintain the integrity and performance of the AI model while ensuring its transparency and accountability.
- Regulatory compliance: Facilitate regulatory compliance by providing a secure and transparent approach to AI development.
PrivateGPT on Kubernetes
Running PrivateGPT on a Kubernetes cluster can provide several benefits.
Here are some reasons why you might consider doing so:
- Scalability: Kubernetes allows you to scale your PrivateGPT deployment horizontally (add more nodes) or vertically (increase CPU/memory resources) as needed, ensuring that your language model can handle increased traffic or computational demands.
- High availability: With Kubernetes, you can ensure that your PrivateGPT service is always available by deploying multiple replicas of the application and using load balancing to distribute incoming requests across them.
- Fault tolerance: If one node in your PrivateGPT deployment fails or becomes unavailable, Kubernetes will automatically detect the issue and restart the container or replace it with a new instance, minimizing downtime and ensuring continued service availability.
- Resource isolation: Kubernetes provides strong resource isolation between containers, which helps prevent a single misbehaving container from consuming excessive resources or impacting other containers in your PrivateGPT deployment.
- Efficient use of resources: By deploying multiple containers on the same host node, you can reduce overhead and improve resource utilization compared to running each container on its own dedicated host.
- Easy management: Kubernetes provides a unified way to manage and monitor your PrivateGPT deployment, including logging, monitoring, and debugging tools.
- Security: Kubernetes allows you to implement robust security policies and network policies to control access to your PrivateGPT service and protect it from unauthorized access or malicious attacks.
- Integration with other services: You can integrate your PrivateGPT service with other Kubernetes-native services, such as databases (e.g., PostgreSQL) or message queues (e.g., RabbitMQ), to create a complete language processing pipeline.
- Flexibility: With Kubernetes, you can choose from various container runtimes (e.g., Docker, rkt) and orchestration engines (e.g., Helm, kustomize) to manage your PrivateGPT deployment, giving you flexibility in how you deploy and manage your application.
- Portability: Kubernetes allows you to easily move your PrivateGPT deployment between environments (e.g., dev, prod) or clouds (e.g., AWS, GCP and of course onto Zadara), making it easier to develop, test, and deploy language processing applications.
Overall, running PrivateGPT on a Kubernetes cluster provides a robust, scalable, and manageable infrastructure for deploying and operating large-scale language models.
Logical Diagram:
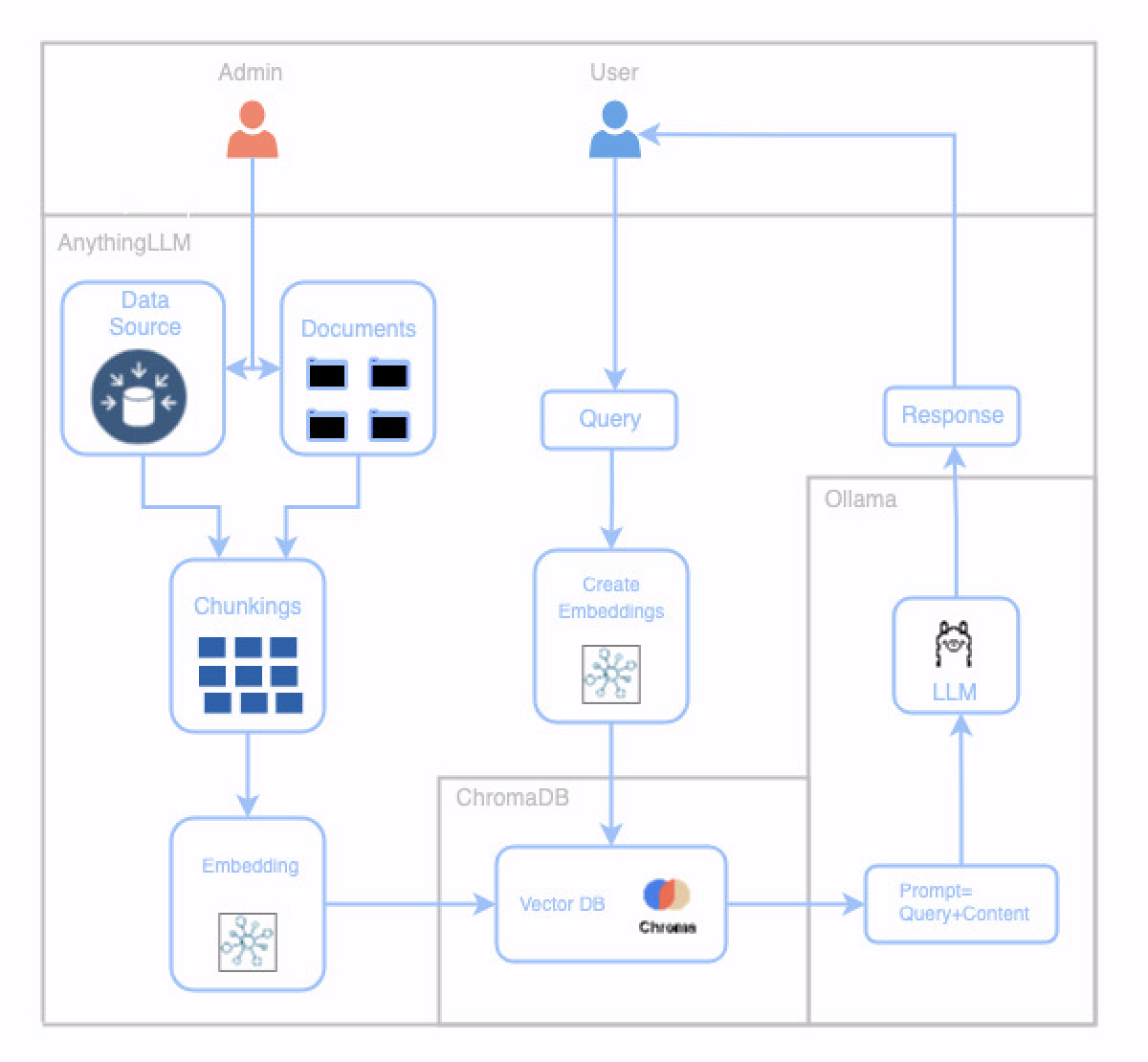
Architecture:
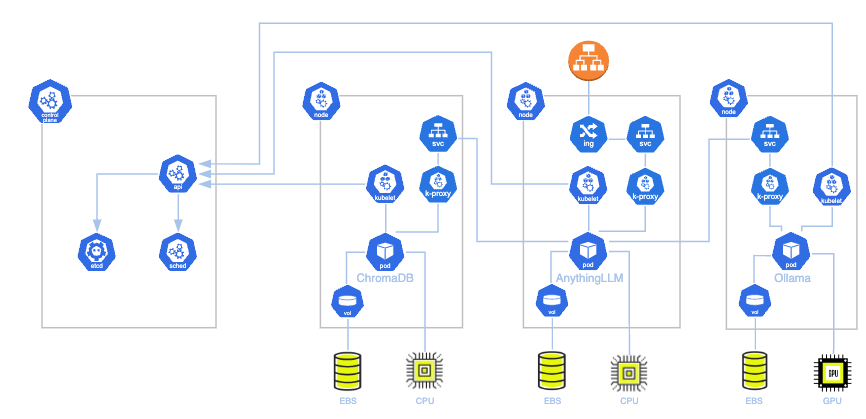
Understanding the AI Data Challenge
Storing large amounts of text data in a traditional database for efficient search and retrieval can be challenging due to its unstructured nature. Vector databases offer a solution by converting text data into numerical representations (vectors) that can be compared efficiently. However, to effectively utilize vector databases, we need to address two key concepts:chunking and embedding.
Understanding the Basics
Before diving into the specifics, let’s clarify two key terms:
- Chunking: Breaking down large text documents into smaller, manageable units.
- Embedding: Converting text into numerical representations (vectors) that capture semantic meaning.
Why Chunking and Embedding?
Large Language Models (LLMs) excel at processing information, but their capacity is limited. To effectively handle large datasets, we need to break them into smaller chunks. These chunks are then converted into embeddings, which allow for efficient comparison and retrieval using vector databases.
The Data Processing Considerations
- Chunking:
- Identify chunk size: Determine the optimal chunk size based on the LLM’s limitations and the nature of the data. Shorter chunks might be better for factual queries, while longer chunks might be suitable for summarizing or generating creative text.
- Define chunk boundaries: Decide how to split the text. Common methods include splitting by sentence,paragraph, or a fixed number of tokens.
- Overlap: Consider overlapping chunks to improve context understanding and retrieval accuracy.
- Embedding:
- Choose an embedding model: Select an appropriate embedding model based on the desired semantic representation. Popular options include Sentence Transformers, BERT, and RoBERTa.
- Generate embeddings: Process each chunk through the embedding model to obtain a numerical vector representing its semantic meaning.
- Storing in Vector Database:
- Index creation: Create an index in the vector database to efficiently store and search embeddings.
- Data insertion: Store the generated embeddings along with their corresponding chunk IDs or metadata in the vector database.
The Role of Vector Databases
Vector databases are optimized for storing and searching high-dimensional vectors. They enable efficient similarity search, allowing you to find chunks that are semantically similar to a given query. This is crucial for LLM applications that require accurate and relevant information retrieval.
Example Use Case
Let’s say you want to build a question-answering system over your organization’s large knowledge base.
- Chunk: Break down the knowledge base into smaller sections (e.g., paragraphs).
- Embed: Convert each chunk into a numerical vector using a suitable embedding model.
- Store: Store the embeddings and their corresponding chunk IDs in a vector database.
- Query: When a user asks a question, convert it into a vector.
- Search: Search the vector database for the most similar chunks based on the query vector.
- Retrieve and Process: Retrieve the original text from the identified chunks and provide the answer using an LLM.
Key Considerations
- Chunk size: Experiment with different chunk sizes to find the optimal balance between accuracy and efficiency.
- Embedding model: Choose an embedding model that aligns with your specific use case and data characteristics.
- Vector database: Select a vector database that offers the right features and performance for your application.
- Computational resources: Embedding generation can be computationally expensive, so consider using pre-trained models or utilizing cloud-based services.
By effectively combining chunking, embedding, and vector databases, you can build powerful LLM applications that can handle large amounts of data and provide accurate and relevant responses. This can drive up employee productivity or if available to external entities in a secure manner could provide details on their account, or enable self service support capabilities.
Why Use AnythingLLM?
AnythingLLM is an all-in-one platform designed to simplify the process of building and deploying custom LLMs. It offers a range of features that make it a compelling choice for both individuals and businesses alike.
Key Benefits of Using AnythingLLM
- Ease of Use: No coding or infrastructure setup is required. The platform provides a user-friendly interface for building and deploying LLMs.
- Customization: You can fine-tune pre-trained models or train your own models on custom data.
- Privacy: Your data remains private as the platform runs locally on your computer.
- Cost-Effective: Avoids the high variable costs associated with many cloud-based LLM services.
- Flexibility: Supports a variety of LLMs and vector databases, allowing you to choose the best options for your needs.
- RAG Capabilities: Enables you to build Retrieval-Augmented Generation (RAG) systems for improved accuracy and relevance.
- AI Agent Functionality: Allows you to create AI agents that can perform tasks and interact with the world.
Why Use ChromaDB?
ChromaDB is a popular choice for storing and managing vector embeddings, particularly in the context of language models and semantic search applications.
Here’s why you might consider using it:
Simplicity and Ease of Use
- Intuitive API: ChromaDB offers a straightforward API that makes it easy to get started with vector databases.
- Minimal Setup: You can quickly set up and start using ChromaDB without extensive configuration.
Flexibility and Customization
- In-Memory or Persistent Storage: Choose between in-memory or persistent storage based on your application’s requirements.
- Customizable Embeddings: You can use your preferred embedding models and integrate them with ChromaDB.
- Metadata Support: Store additional information alongside embeddings for richer queries and filtering.
Open-Source and Community
- Active Development: ChromaDB is an open-source project with a growing community and active development.
- Cost-Effective: As an open-source solution, it’s often more cost-effective than proprietary alternatives.
Use Cases
- Semantic Search: Find similar items based on their semantic meaning.
- Recommendation Systems: Suggest items based on user preferences or past behavior.
- Question Answering: Retrieve relevant information from a large dataset based on a query.
- Image and Video Search: Find similar images or videos based on visual content.
Comparison to Other Vector Databases
While ChromaDB is a strong contender, it’s essential to consider other options like Pinecone, Milvus, and Weaviate based on your specific needs. Factors like scalability, performance, cloud integration, and pricing may influence your decision.
Why Use Ollama?
Ollama is an open-source platform designed to make running LLMs locally more accessible. It offers several advantages:
Key Benefits of Using Ollama:
- Local Control: You retain full sovereign control over your data and the LLM environment.
- Offline Capability: Run models without an internet connection, ideal for privacy-sensitive applications or areas with limited connectivity.
- Customization: Fine-tune models to specific tasks or domains.
- Cost-Effectiveness: Avoids many cloud-based costs and potential API limitations.
- Open Source: Benefit from community contributions and transparency.
Ideal Use Cases:
- Privacy-Centric Applications: When data security is paramount.
- Offline Environments: For scenarios without reliable internet access.
- Custom Model Development: To fine-tune models for specific tasks.
- Cost Optimization: For those seeking to reduce expenses associated with cloud-based LLMs.
However, it’s important to note that:
- Resource Intensive: Running LLMs locally usually requires significant computational resources (GPU), especially if deploying for scale.
- Model Maintenance: Keeping models up-to-date can be time-consuming.
If you prioritize control, privacy, and cost-efficiency, Ollama can be a valuable tool to enable you to gain more efficiencies from your data.
Deploying PrivateGPT with Taikun and Zadara
These steps presume you have already completed the steps in the previous blog articles on setting up a Zadara VPC and establishing a Taikun Cloudworks environment
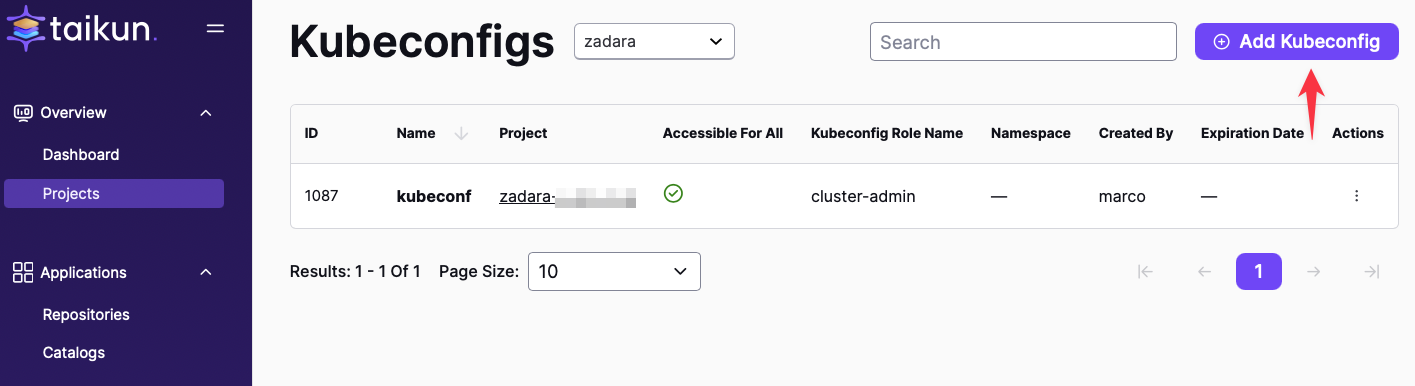
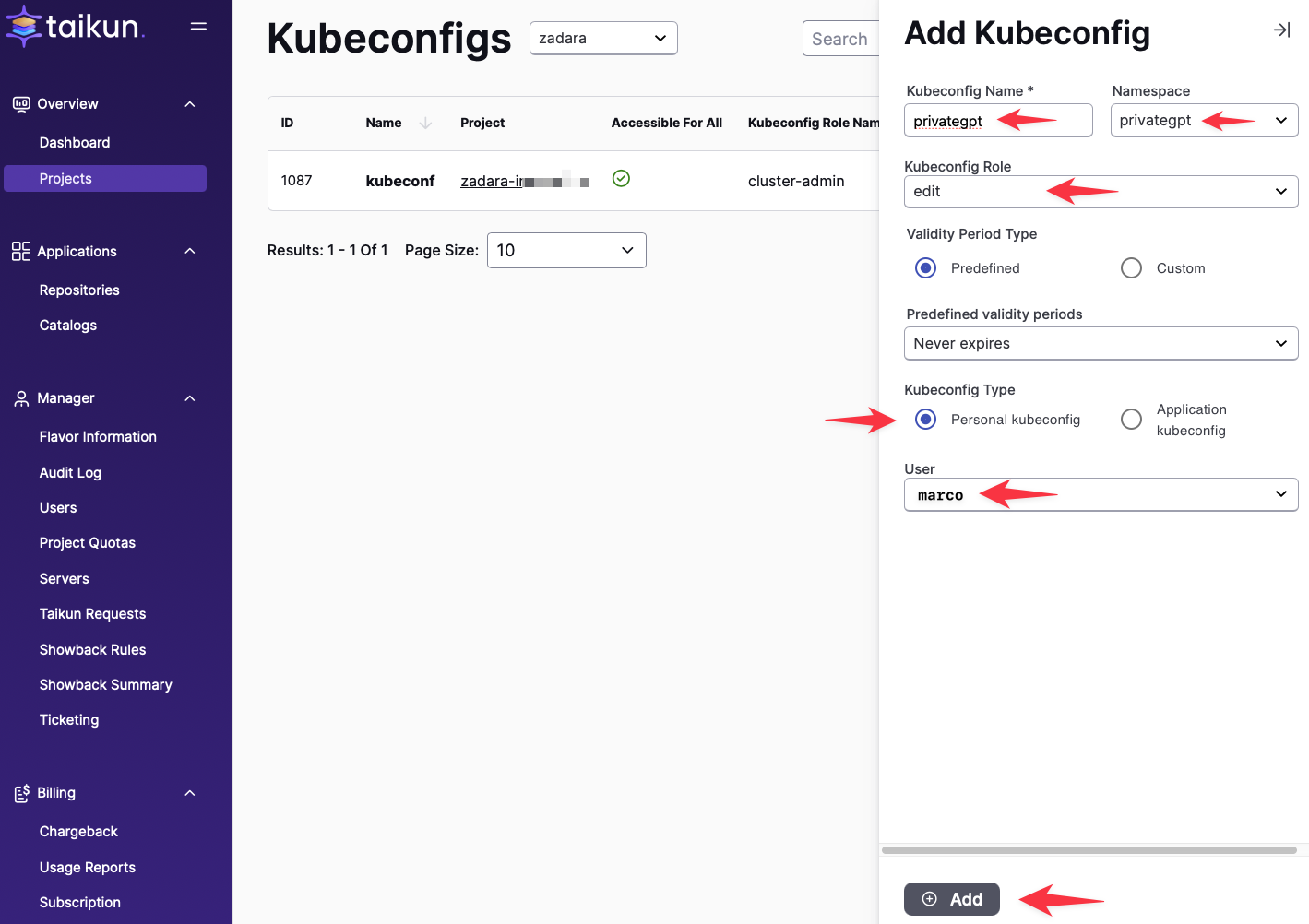
Generate Kubeconfig:
Zadara zCompute incorporates an Elastic Load Balancer (ELB) that we will leverage to enable external HTTPS access to our AnythingLLM application. Unfortunately, this configuration cannot currently be achieved only through the Cloudworks GUI and necessitates the use of the Kubernetes CLI (kubectl) tool.
Prior to commencing, a kubeconfig file is required. This file should be located at the .kube/config path. For comprehensive instructions on obtaining and configuring a kubeconfig file, please consult the official Kubernetes documentation.
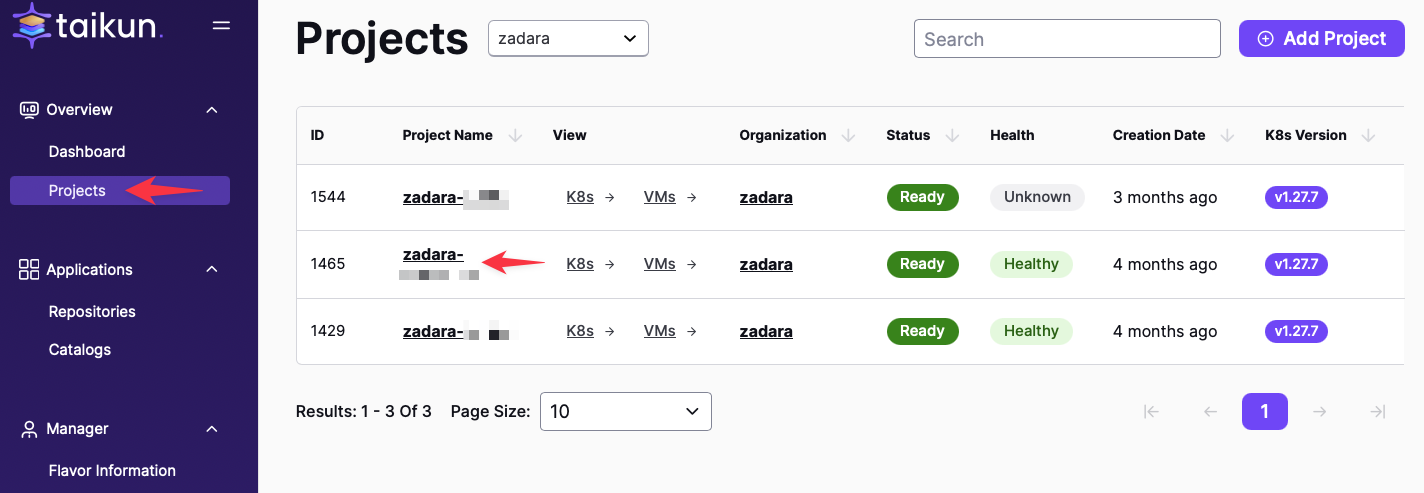
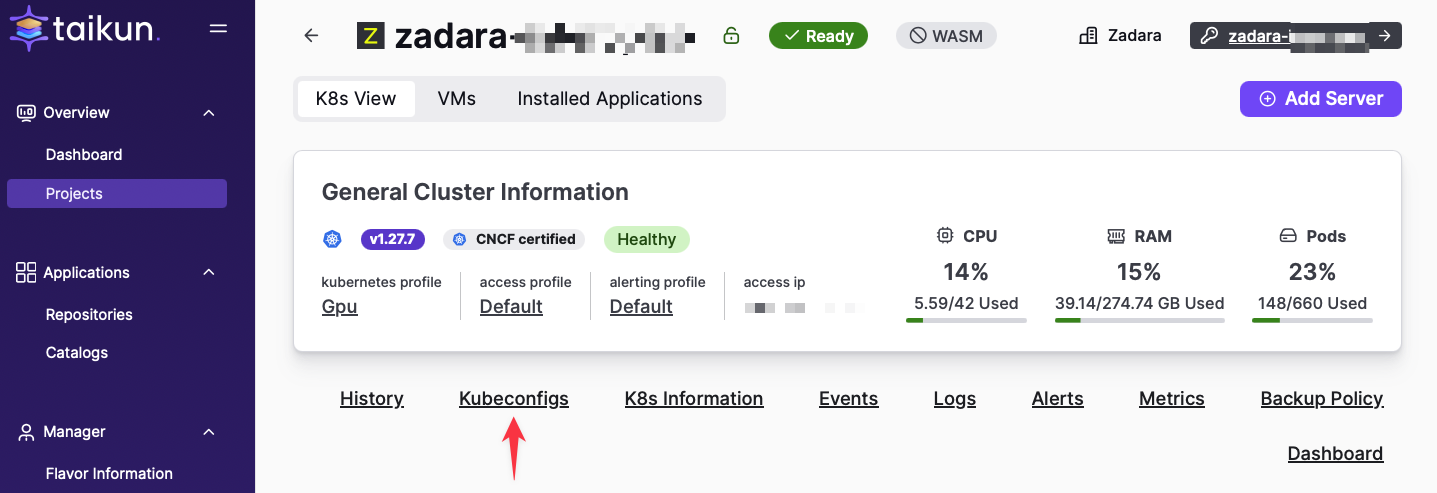
Installing Ingress:
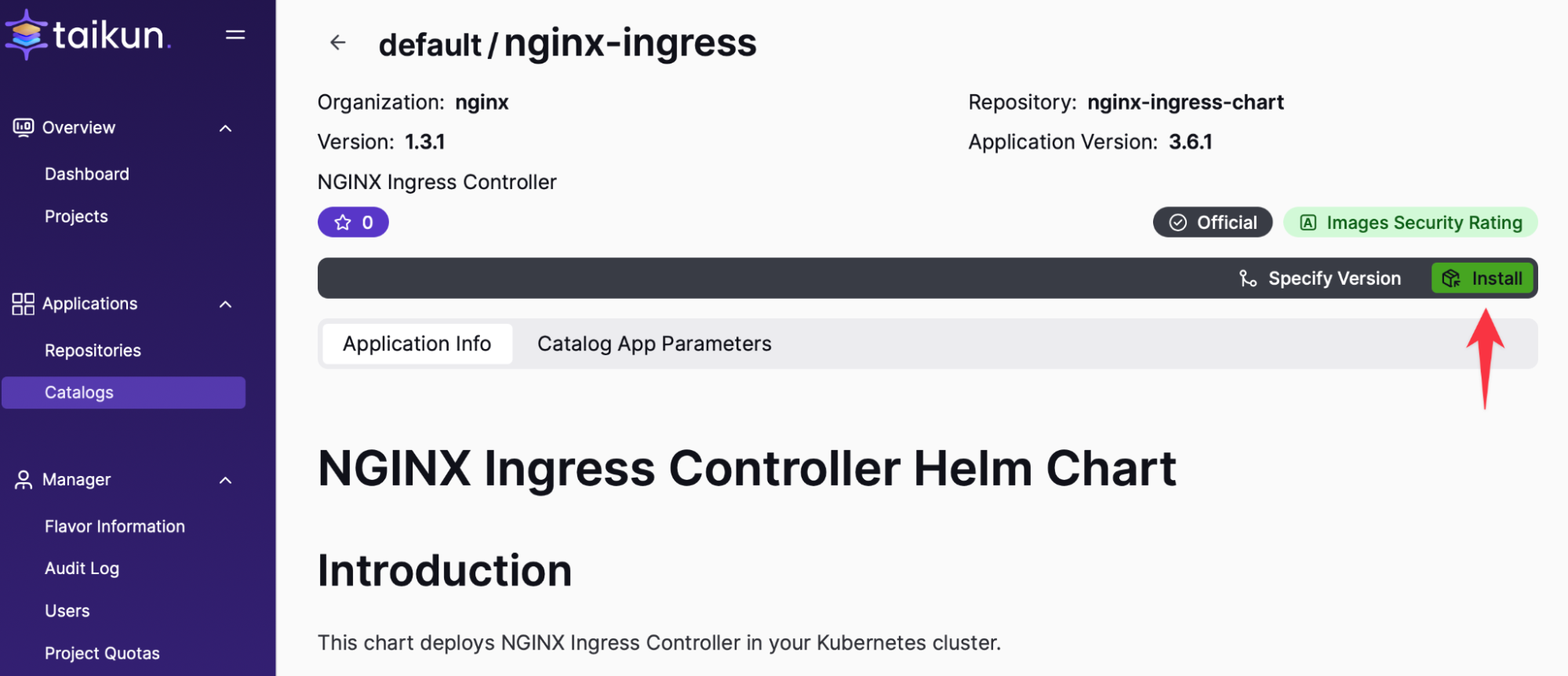
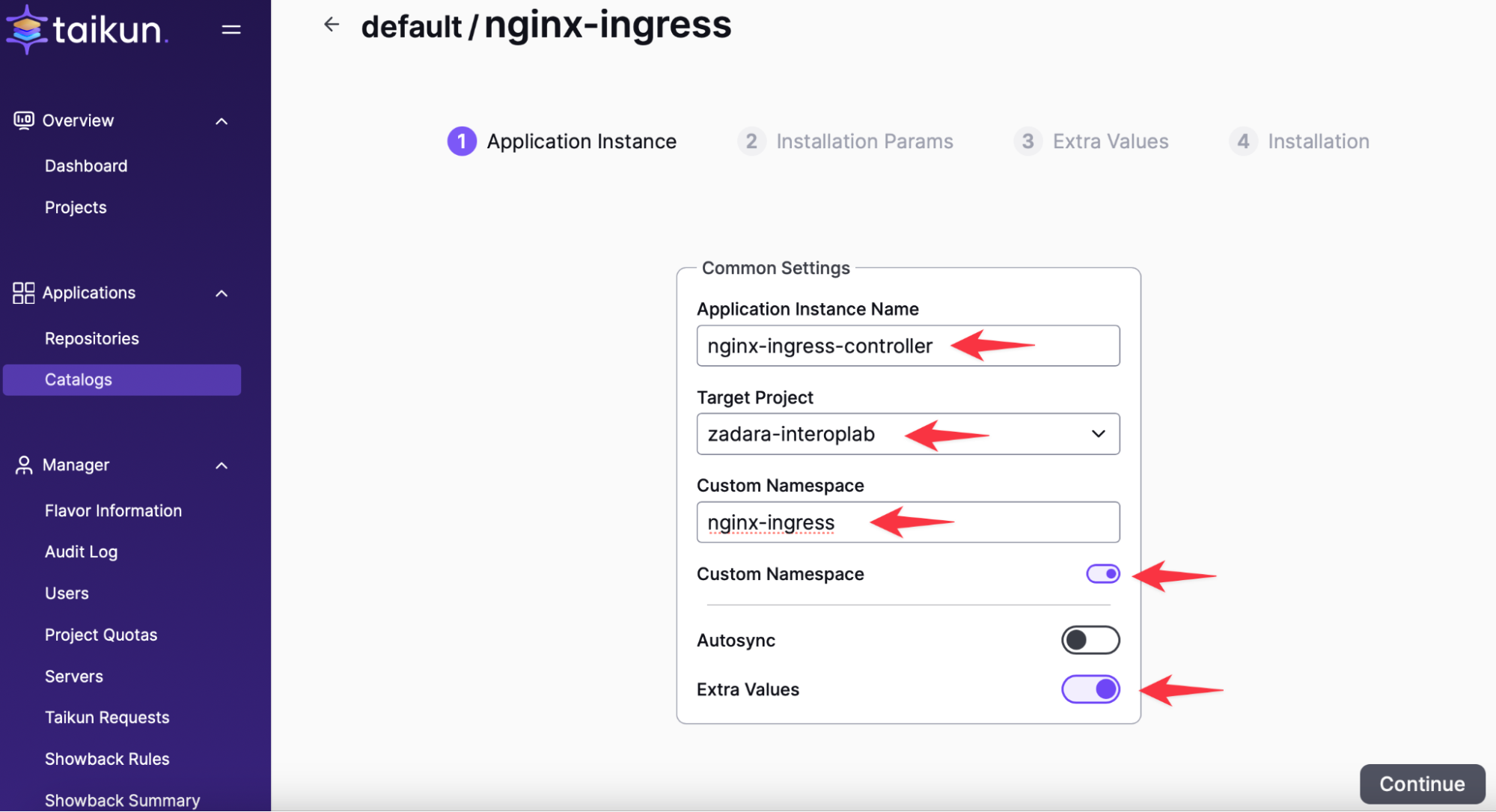
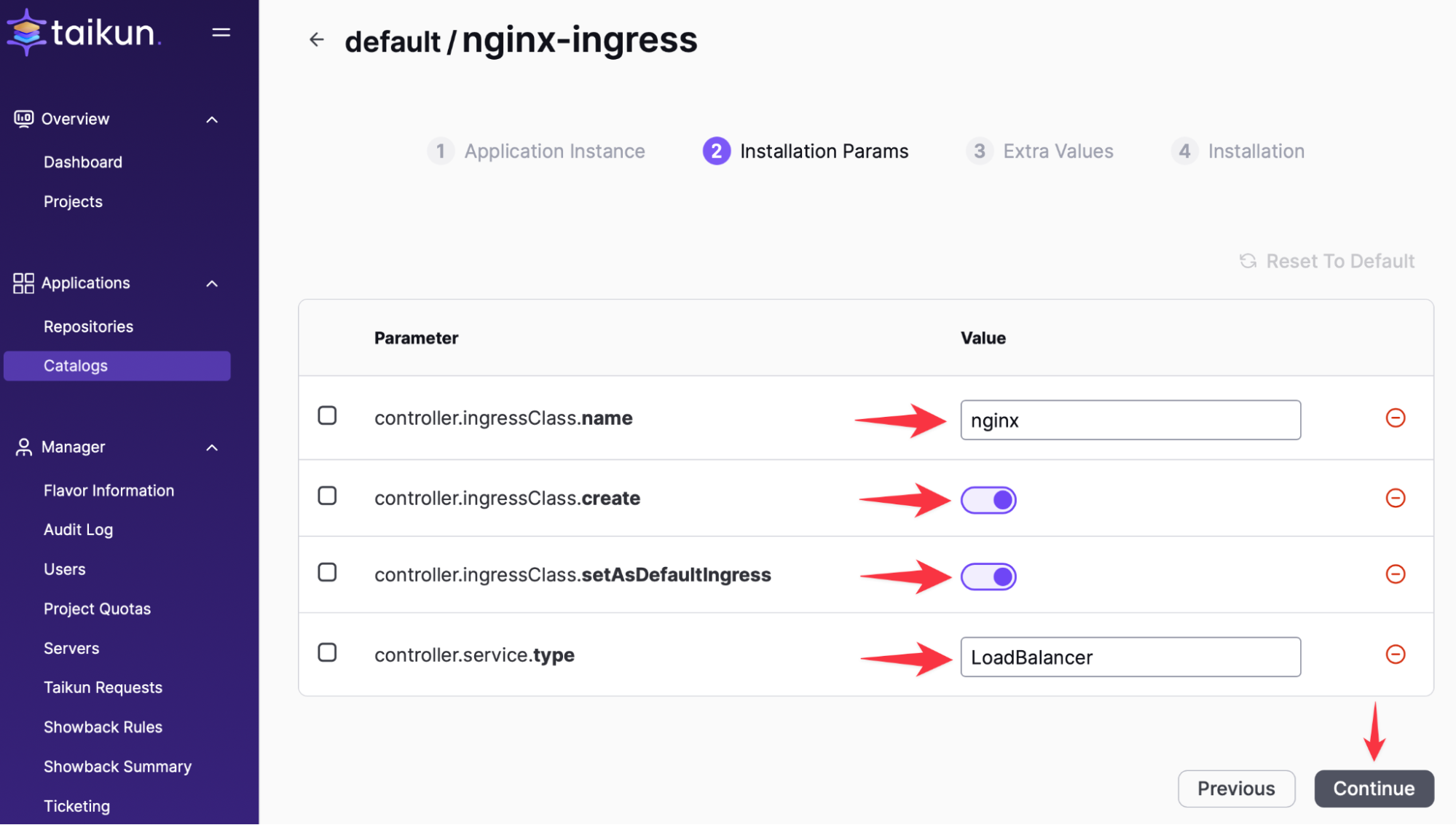

After a couple of minutes, the Load Balancer is ready for the Ingress-controller.
You can check the external IP with the following command:
kubectl get svc nginx-ingress-controller-controller -n nginx-ingressUse this external IP for your DNS entry (like Cloudflare).

To use https you need a certificate. You can easily create a self signed certificate or get one from your DNS provider such as Cloudflare.
openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-out your-cert.crt -keyout your-key.key \
-subj "/CN=your-url" \
-reqexts SAN \
-extensions SAN \
-config <(cat /etc/ssl/openssl.cnf \
<(printf "[SAN]\subjectAltName=DNS:your-url"))
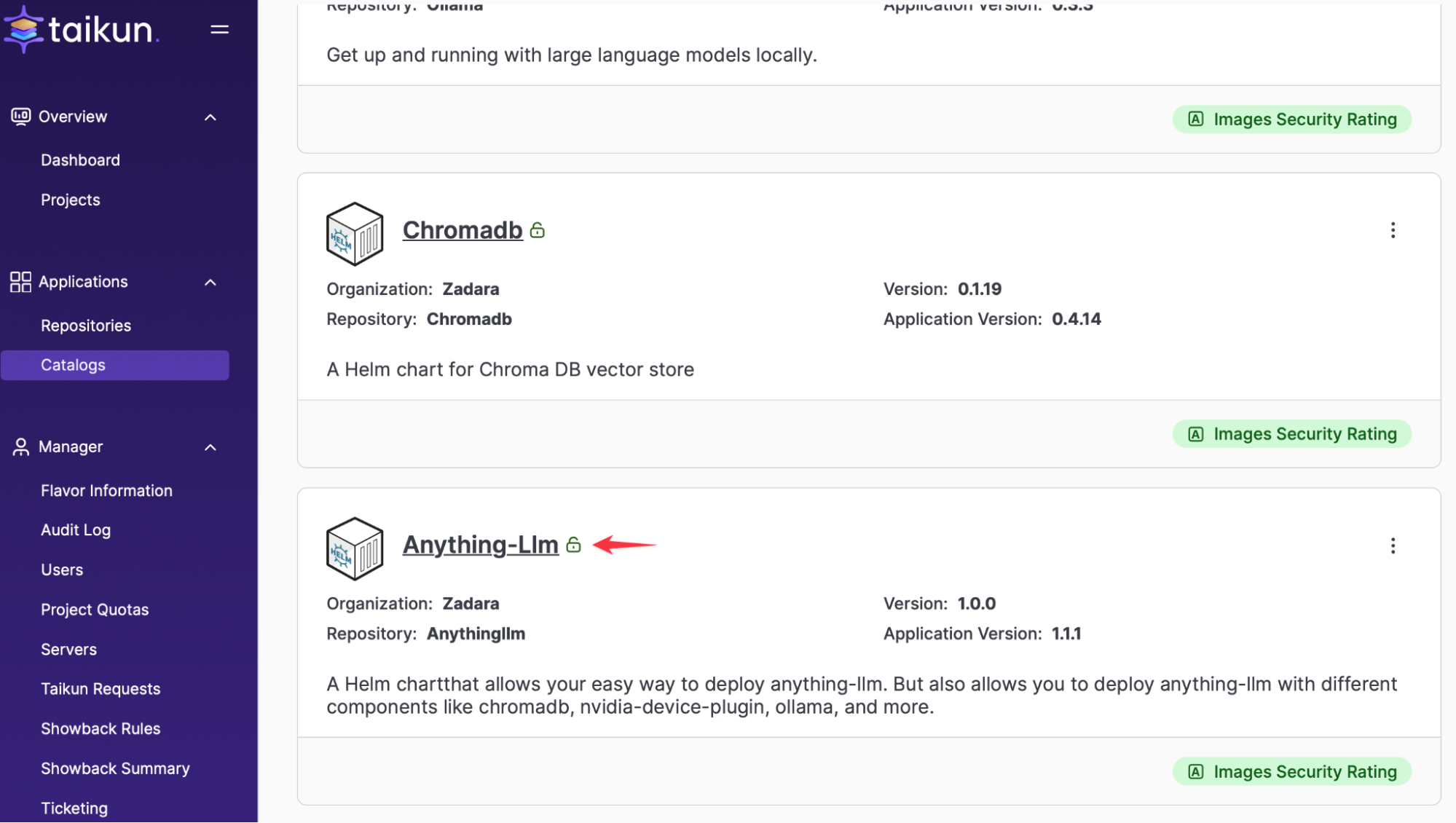
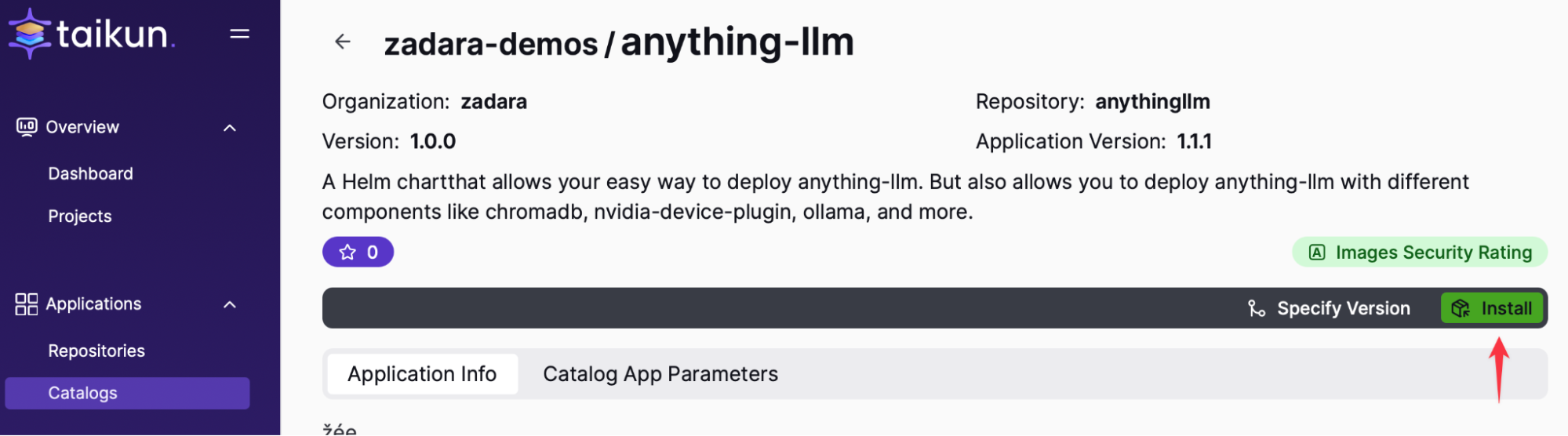
Install AnythingLLM on Cloudworks:
For simplicity we have used a helm chart that brings all 3 components together, AnythingLLM, ChromaDB and Ollama. The Helm chart requires 2 namespaces, one for the backend services and one for the frontend portal. We will name the backend namespace > llm-backend and the frontend is automatically named anythingllm
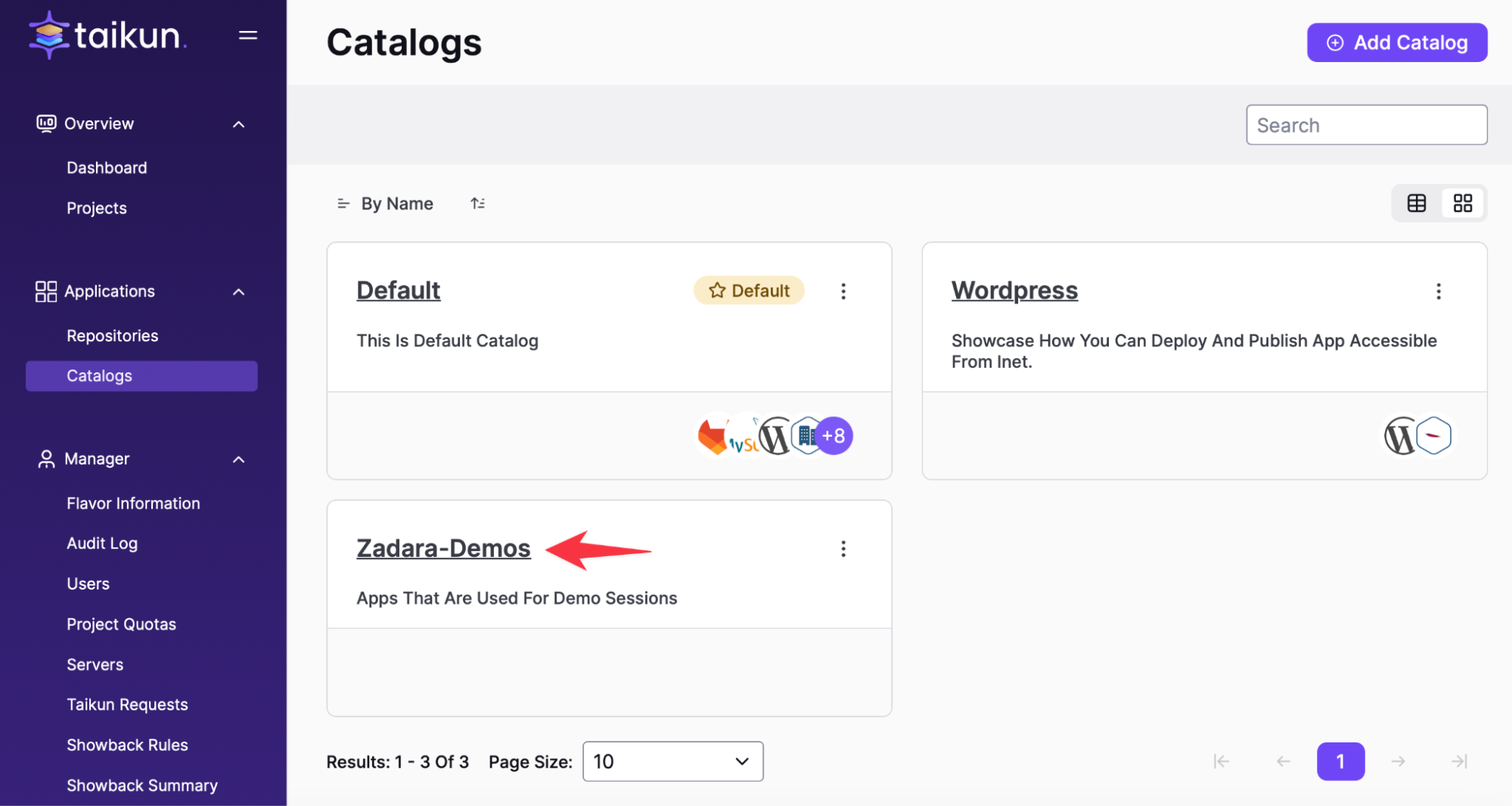
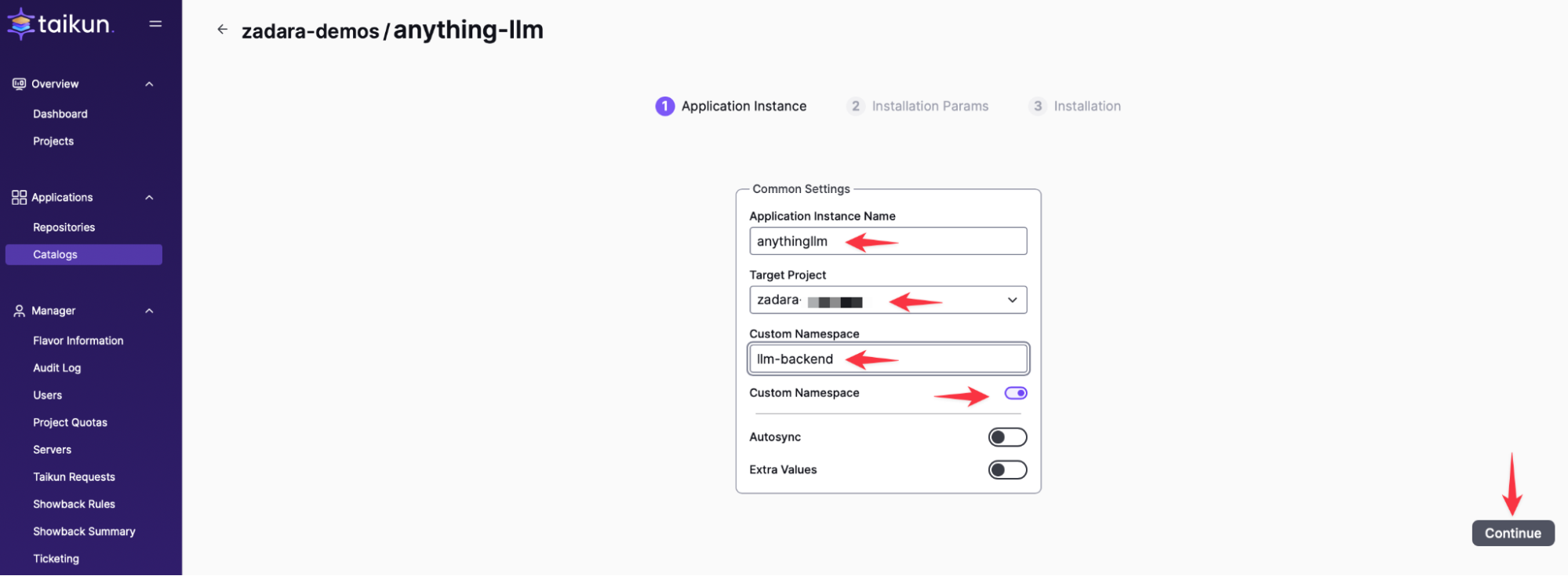
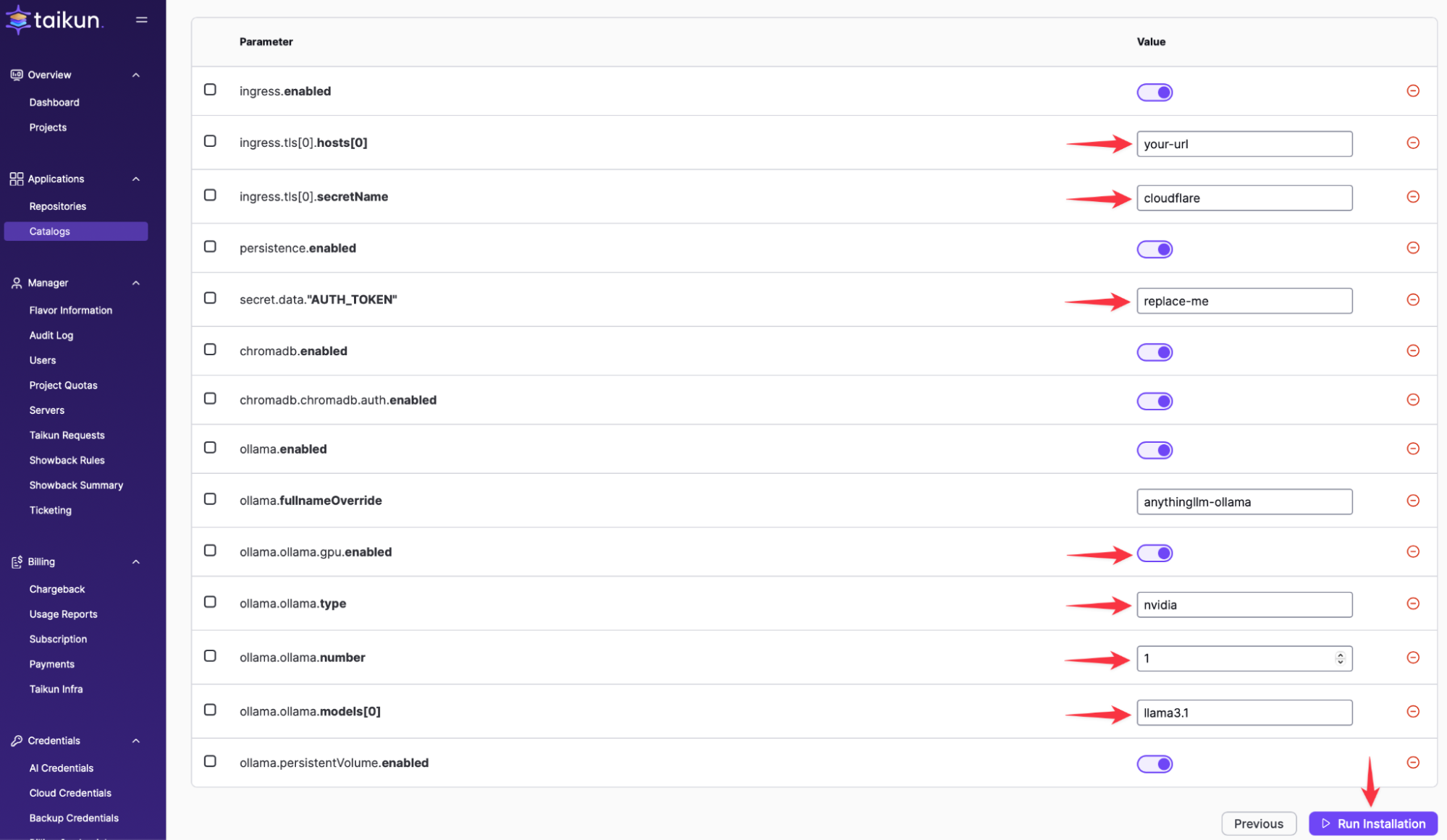
Change all settings based on your DNS and specific environment setup.
Depending on your GPU type and amount, please update the parameters. Ollama supports AMD, NVIDIA and INTEL GPUs. In this specific demo, We have used one L40 NVIDIA GPU in a single Worker Node.
Customize AnythingLLM:
Now it’s time to upload the certificate to kubernetes.
To upload the certificate we use the following command:
kubectl create secret tls cloudflare --key your-key.key --cert your-cert.crt -n anythingllm
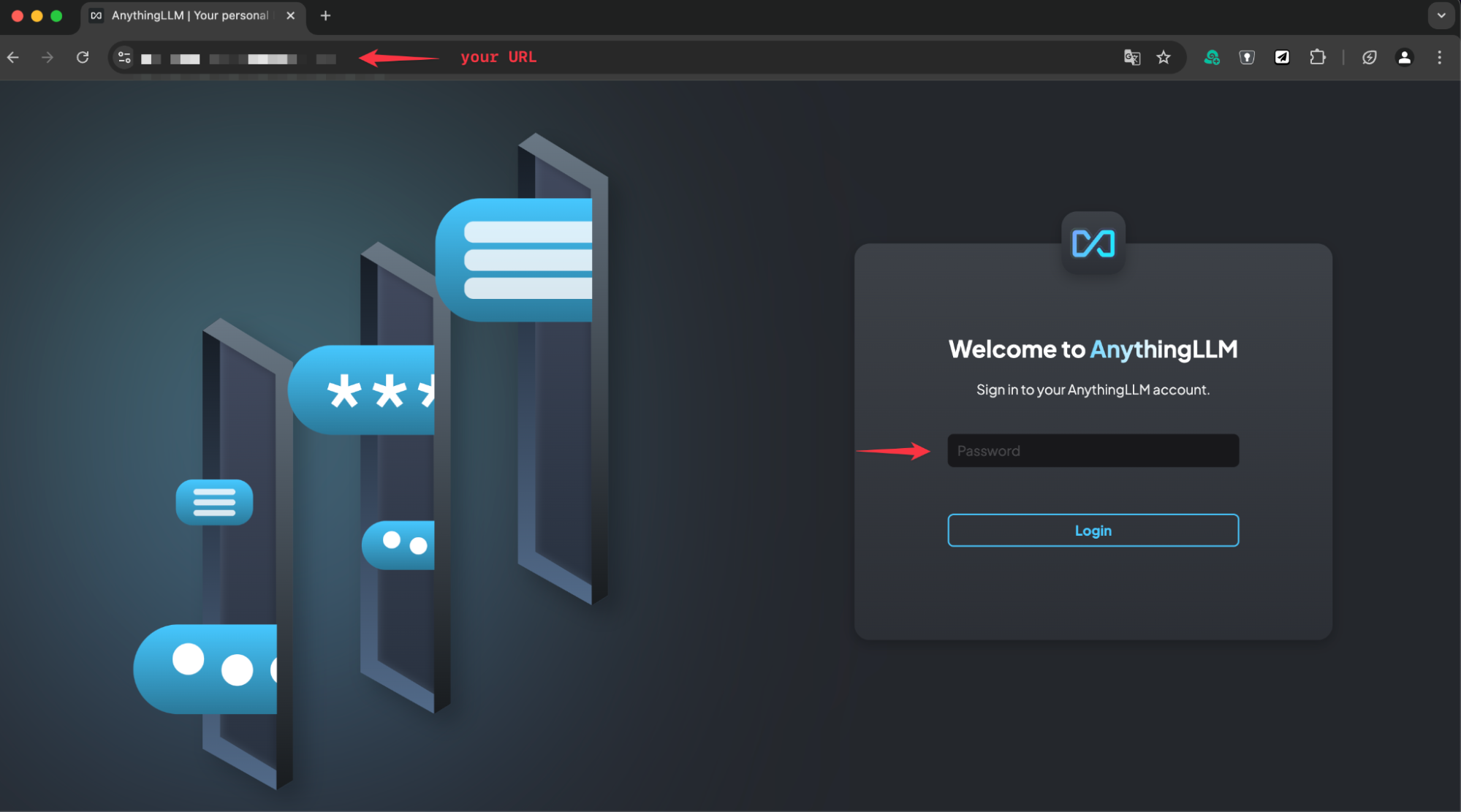
Once this is complete, we are ready to open a browser and login to AnythingLLM. Use your URL that you configured in the previous step.
The initial password is defined in secret.data.AUTH_TOKEN” and is in this example “replace-me”.
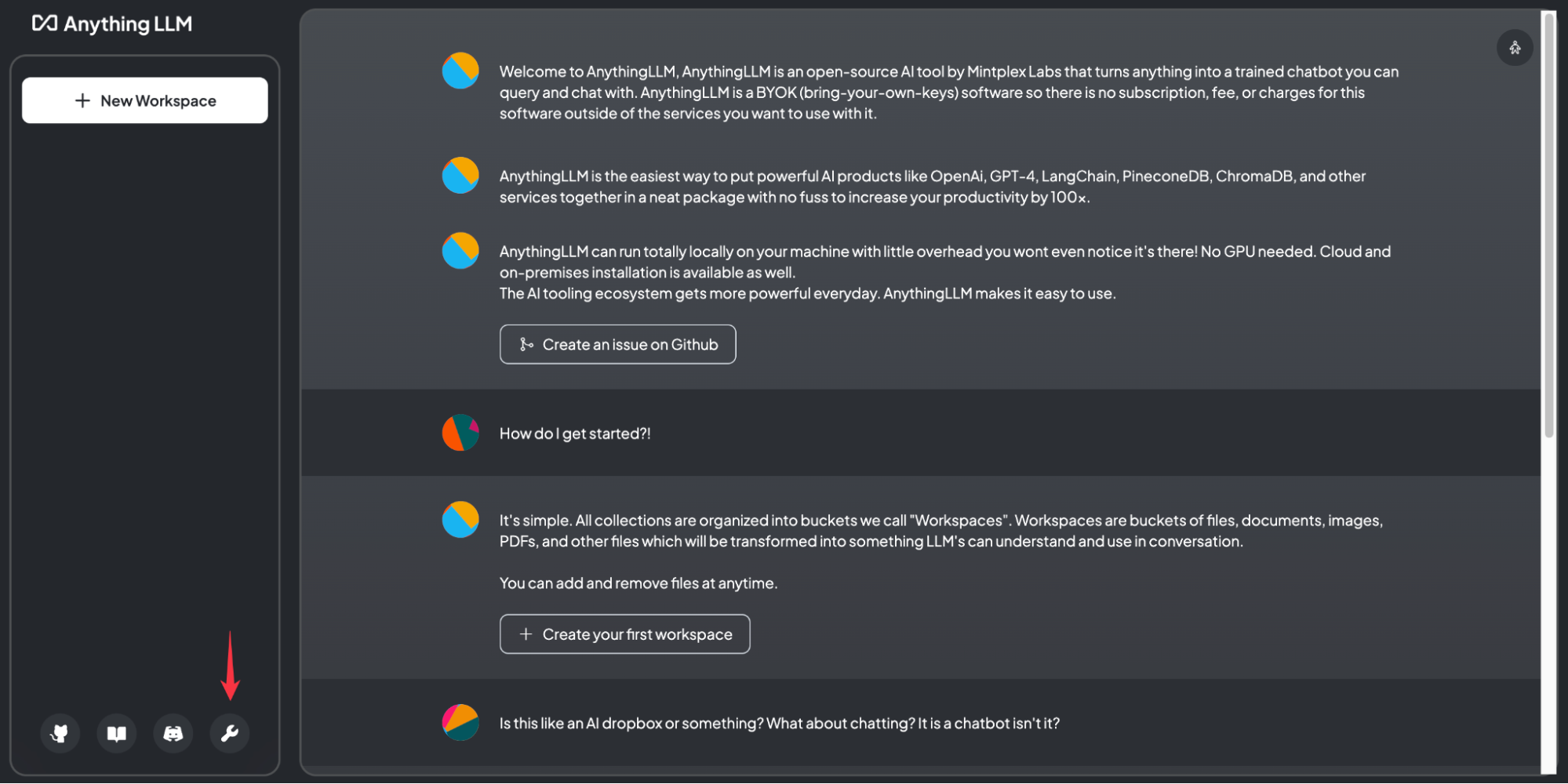
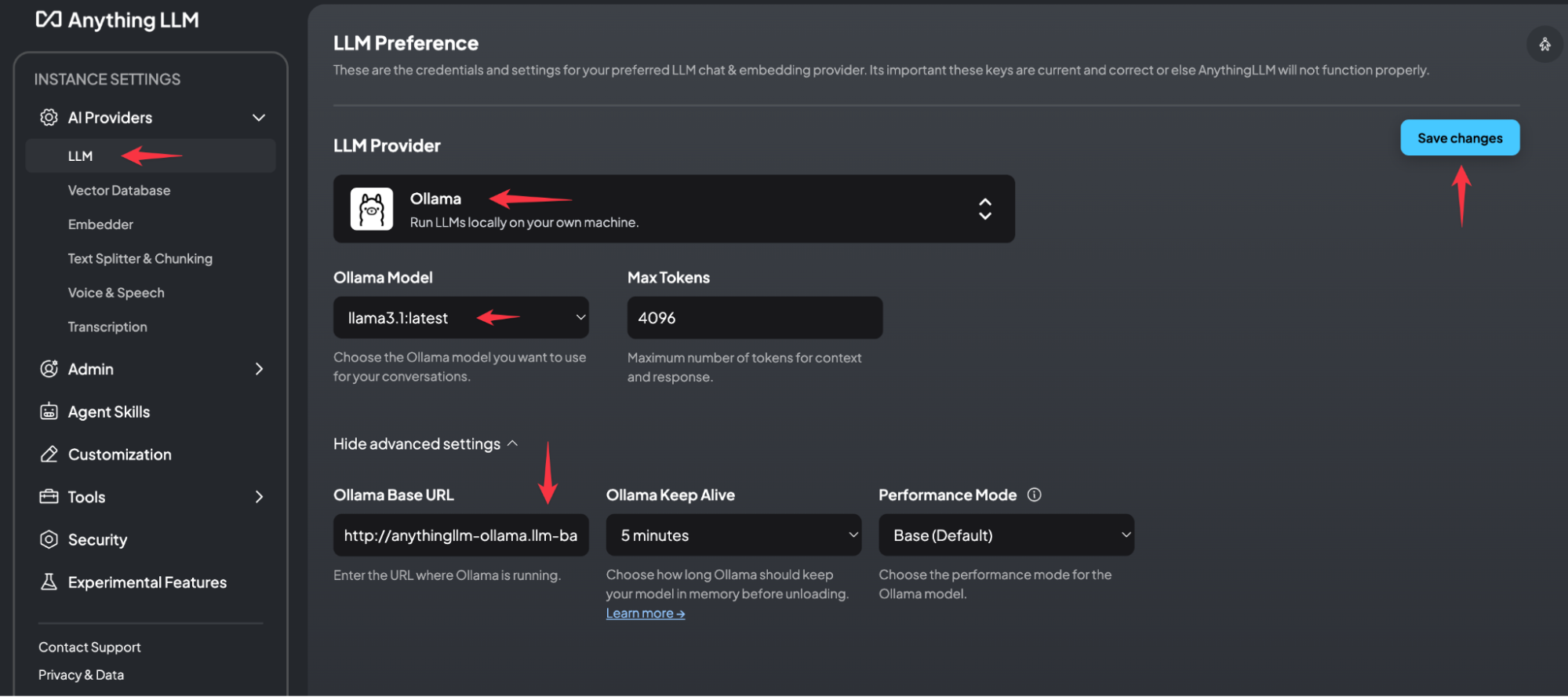
First we must define the LLM Provider. In this example we have installed everything together and Ollama is placed in the llm-backend namespace.
The URL we use is http://anythingllm-ollama.llm-backend.svc.cluster.local:11434. If the URL is correct, the System automatically finds the Ollama Model.
Next, the definition of the Vector Database is required.
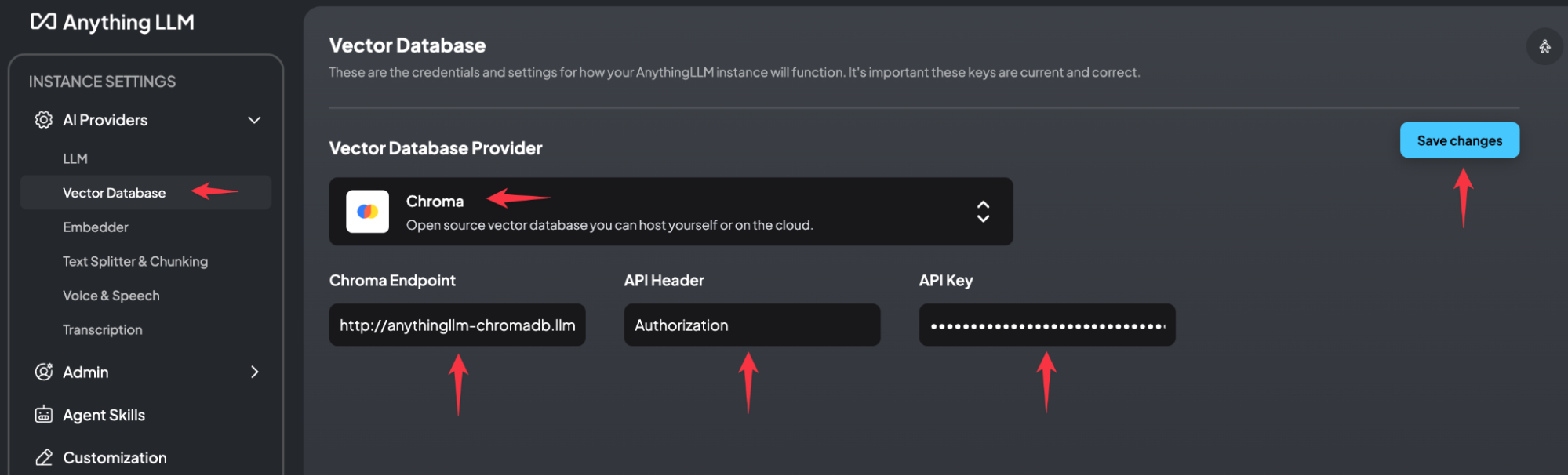
The URL we use is http://anythingllm-chromadb.llm-backend.svc.cluster.local:8000
The default API Header is Authorization and the API key can we received with the following command:
kubectl get secret chromadb-auth -n
llm-backend -o jsonpath="{.data.token}" | base64 --decode
Now we can start using your own PrivateGPT running on Taikun Cloudworks and Zadara
Conclusion
By leveraging Taikun CloudWorks on Zadara for modern application deployment, you can significantly reduce operational overhead and focus on what matters most – delivering exceptional IT services.
With its intuitive interface, pre-configured templates, and powerful management features, Zadara takes the complexity out of infrastructure and Taikun CloudWorks builds on top of this for application deployment, allowing you to streamline your workflows and achieve greater efficiency.
You can gain the collective power from your data to provide additional business value from a sovereign AI deployment.



